The Perl and Raku Foundation (TPRF) provide community grants for work that is valuable to the Perl and Raku communities.
The purpose of this page is to provide a resource for community members to record ideas that might be appropriate for TPRF community grant funding.
- If you are looking to work on a grant to help the community, take a look at this list.
- If you have suggestions for useful work (whether for the communities or for the languages), please open an issue or submit a pull request and, once approved, it will show up here.
While we try to keep this list relevant, things can easily get out of date. Before grabbing a task, check that a similar investment is not done recently.
⚠️ Disclaimer The list does not guarantee that TPRF will fund any grant proposal based on them. All grants must go through the submission and evaluation process.
Perl
Perl core
readpipe(LIST) (from @rjbs)
From the Perl todo:
system() accepts a LIST syntax (and a PROGRAM LIST syntax) to avoid running a shell. readpipe() (the function behind qx//) could be similarly extended.
Unused lexicals (from @rjbs)
From the Perl todo:
This warns:
$ perl -we '$pie = 42'
Name "main::pie" used only once: possible typo at -e line 1.
This does not:
$ perl -we 'my $pie = 42'
Logically all lexicals used only once should warn, if the user asks for warnings. An unworked RT ticket (#5087) has been open for eleven years for this discrepancy.
pack and unpack on streams (from @tux)
Currently, pack and unpack work on a string, which means that you have to move forward in the data-string yourself, if the full data-format is not known in advance, but depends on data seen so far.
If one could unpack on a stream, one could unpack the picture that is known, have the stream pointer move forward the amount of data read from the given picture, and be ready to read the next data based on a next, possibly different) picture.
Extreme “win” can be taken where the size of the data being read for a given picture is differing per architecture, like native floats.
Learning Perl
Code Combat support for Perl.
https://codecombat.com is a great website for introducing programming to kids. The language they use is Python by default but you can switch to other languages. This could also be a great tool for learning Perl.
When they were asked in their slack, they responded to the idea of adding Perl:
It’s a bit tricky, but doable. This is the open-source code interpreter we made for this: https://github.com/codecombat/esper.js – to add new programming languages for CodeCombat, we add plugins to Esper to support them. A plugin consists of a parser for the language (implemented in JavaScript, parsing to Mozilla-JavaScript-compatible AST) and a JavaScript runtime that implements the needed semantic differences between normal JS behavior and the target language. That’s how we have JS, Python, CoffeeScript, Lua, Java, and C++.
CPAN
PSGI protocol for HTTP::Tiny
Enhance HTTP::Tiny to support it communicating via PSGI. The primary use case being to assist in testing. See also LWP::Protocol::PSGI and Furl::PSGI.
Convert CHI::Driver::Memcached to Moo
The base CHI of the Caching Handler Interface was swapped from Moose to Moo in v0.58 (v0.60 being current). Arguably the most common Driver CHI::Driver::Memcached for Memcache still uses Moose. Swapping this driver would reduce the footprint of this common configuration and benefit everything that uses it. Other common backends might also get the same treatment as part of a grant.
Net::Google::Calendar authentication failure
This library no longer works as it uses the Calendar v2 API which Google discontinued. It needs to be updated to the new API (v3).
Module to handle OData (from Alex aka ASB)
We (the Perl community) currently do not have a CPAN module that handles OData. There seems to be an attempt to do it in OData::Client but it’s not finished yet, and I fit doesn’t get a care taker, it will never be done. Also, there is client and server parts. Let’s get both :)
Side node: Eventually, I’m too dumb to see that we don’t need one because Perl can do it out oft he box. But if this is the case, eventually, it would be a good idea to put up a grant to create a document describing how to use OData with Perl (like this one).
Tooling
A regularly updated compendium of Perl IDEs to be hosted on perl.org
Results of the (survey of newcomers to Perl)[https://news.perlfoundation.org/post/newperluserssurvey] indicate that we need a page on perl.org listing IDEs supporing Perl, indicating whether they’re being actively maintained, a brief summary of their functionality and links to where you can learn more.
This page will need to be regularly updated.
Existing attempts
The following attempts at this have not been maintained
- https://www.perlmonks.org/?node=Perl%20Development%20Tools
- https://perl-begin.org/IDEs-and-tools/
- https://en.wikipedia.org/wiki/Comparison_of_integrated_development_environments#Perl
- https://perlmaven.com/perl-editor
Examples of IDEs to cover
Update PPI for more recent constructs (from @rjbs)
Last I looked, PPI couldn’t handle much newer than Perl v5.10 or v5.12. I don’t have a comprehensive list of the stuff it can’t do, but it wouldn’t be tiny. Make it all work.
Push to have Perl support in github code navigation
Github is currently the major social network for developers and provides a good exposure for the Perl modules/code and a nice tool for helping Perl developers (both coding and CI/CD through github actions or travis ci, circle ci or whatever).
Github is experimenting/putting in place the code navigation.
Below the alert to introduce this new feature to developers :
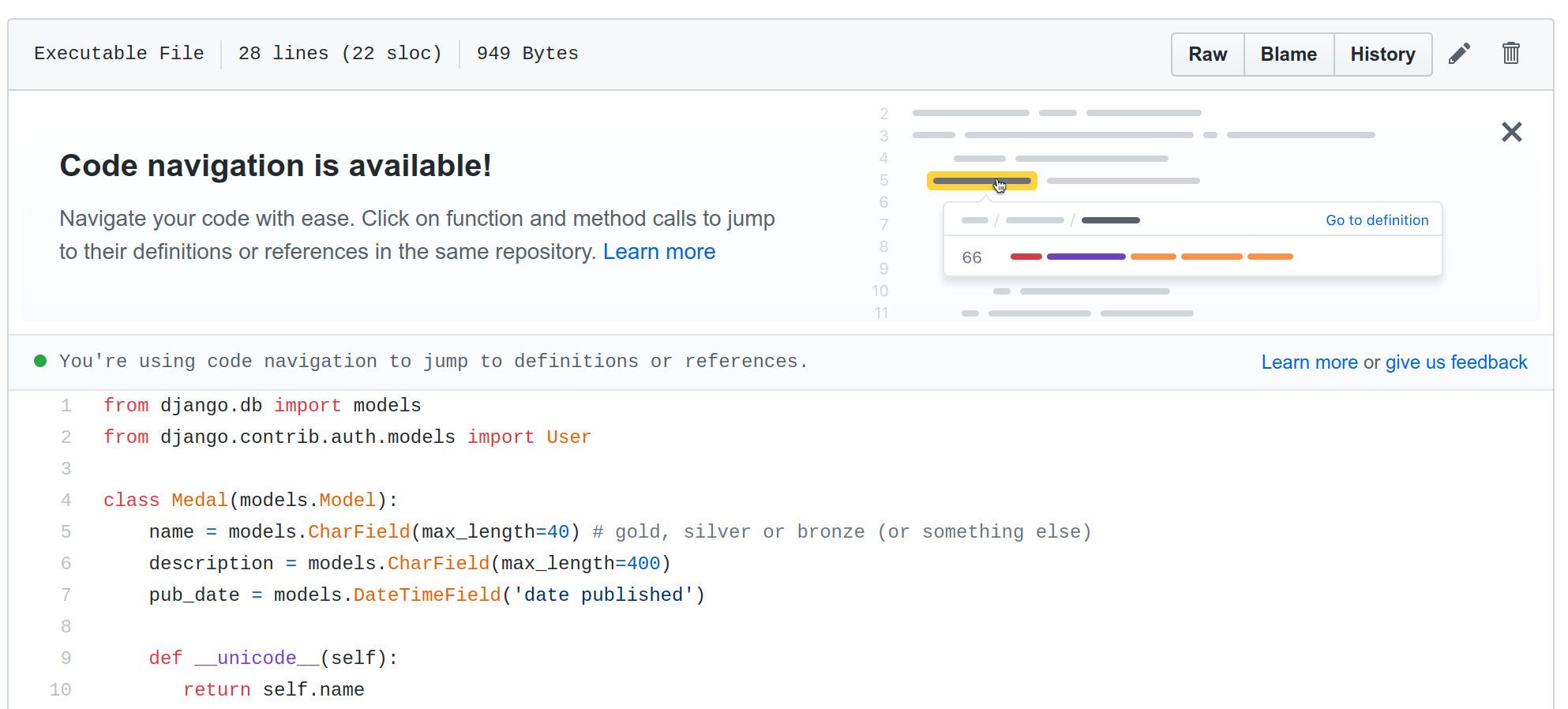
And next a real life working example :
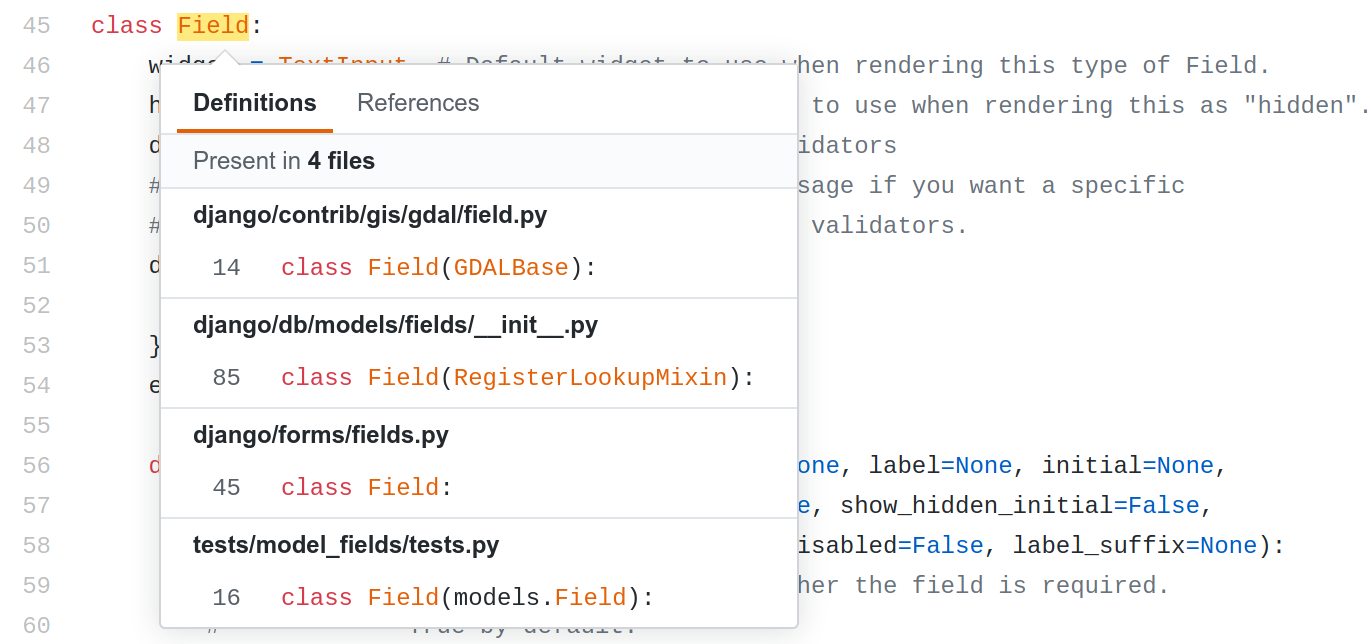
It is available since november 2019 (see the annoucement) and I guess it will grow as this feature is just a “must have” for developers (we have multiple code browsers in my company : bitbucket native, grok and woboq !).
The doc of github says that it is based on semantic which does not support Perl as of today.
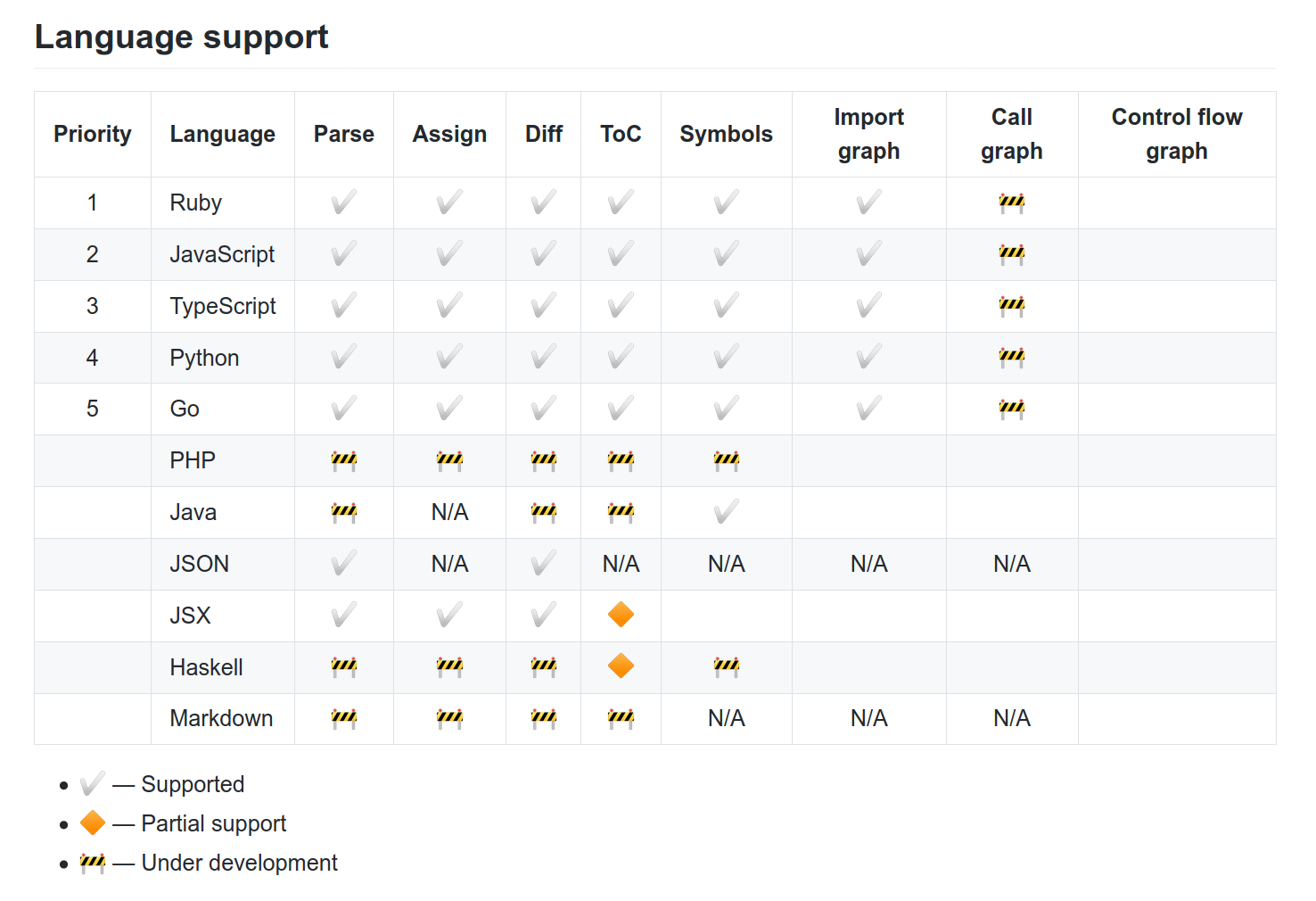
The purpose of this grant would be to :
- Implement Perl support in semantic
- Push Github folks to enable it (first as experimental) - maybe it could be discussed even before implementation :)
It is written in haskell (and in the past Perl and Haskell folks were good friends right ? :P)
Some resources that could help Write Yourself a Scheme in 48 hours (Haskell tutorial), a Haskell based parser for a Perl like language or a Perl 5 grepping tool or isomorphic code written in haskell.
Documentation
DBIx::Class re-documentation (from @ribasushi)
Fixing up the better-than-most-but-still-terrible documentation of DBIC is a ~200 person-hour undertaking, which on top of that requires someones fresh eye.
Given that DBIx::Class is a “staple-module” in the contemporary Perl ecosystem, I believe it is reasonable to expect for the TPF to “pick up the tab” if someone with the right qualifications steps up.
Accessibility
Review and Recommend Standards
As a precusor to inform further work, draft a taxonomy of standards and benchmarks pertinent to accessibility for websites and their content. Make recommendations as to which should be adopted by the TPF and hopefully by well known Perl mastheads. (See also this metacpan bug)
Benchmark, assess, and plan
Benchmark and assess TPF websites and online assets based upon the approved standards. Create a plan of action with milestones and additional potential grant projects to towards compliance with the adopted standards.
Delivery on accessibility
All the milestones that will deliver on accessibility.
Raku
Raku core
Raku ecosystem
SparrowHub
SparrowHub is a repository of Sparrow plugins - reusable scripts for various automation tasks. Plugins are written on many languages and get run eithor by cli or through a programmatic Raku API. Both Raku and Perl community might gain an advantage of plugins eco system easing developers life. SparrowHub could be thought as a MetaCPAN/Raku modules but with more practical approach - find a plugin and run it straight away. It’s dead easy to create new plugins and distribute them.
So a proposal is:
- Finishing SparrowHub site development ( site UI improvements, getting better DNS name, logo creation, so on )
- Finishing plugins migration to a new version of Sparrow ( see this roadmap )
- Adding new plugins are of the interest for both Raku and Perl communities. ( Some Raku/Perl related plugins could be found on SparrowHub )
Tooling
The MoarVM and Rakudo CI toolchains on GitHub (using Travis CI, CircleCI, and AppVeyor) could have a number of enhancements added. Here are three things in particular:
- Code coverage: There is some automation of MoarVM coverage reports when running the NQP test suite here, but that could be expanded to include results from running the Rakudo test suite as well a Roast spectest. Additionally, Rakudo can produce coverage reports of its code, that would also make sense to automate for its test suite and a Roast spectest.
- Benchmarking: There are some benchmarks that are run every day, but the results have been broken for about two years.
- Regression tests: Blin could be run automatically (e.g., at every NQP bump, every 10 or so Rakudo commits).
Documentation
Document Red
Provide user documentation to the revolutionary Red ORM
Add code examples
Allow adding of notes (such as code examples) with the documentation, as is done on the PHP documentation site, e.g. PHP pcre documentation page